Cost-based Optimization¶
The way the optimizer makes its decisions on how to execute queries is based on a methodology called cost-based optimization. A simplification of this process is as follows:
- Assign a cost to each operation.
- Evaluate how many operations each possible plan would take.
- Sum up the total.
- Choose the plan with the lowest overall cost.
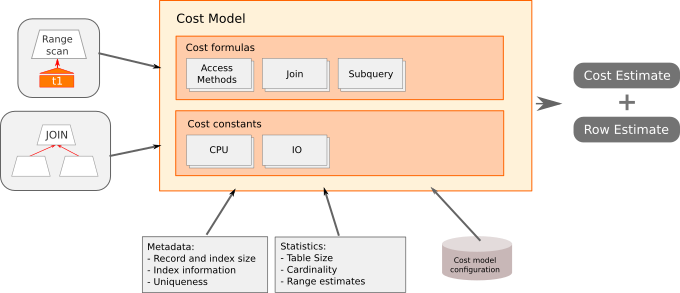
Why I said that the above is a simplification, is that the optimizer does not exhaustively search each possible execution plan. If there are 5 tables to be joined, each with 5 possible indexes, there could be over 5! * 5! = 14400 ways that the query could be executed:
- Each index may have more than one potential access method. (e.g., index scan, range scan, or index lookup). Additionally, each table could potentially use a table scan.
- For an
INNER JOINquery, the tables could be joined in any order (the order the tables are specified does not matter). - When joining there may be multiple join buffering methods or subquery strategies available.
It is not feasible for the optimizer to evaluate each potential execution plan. For example, consider the case that optimizing takes longer than execution. For this the optimizer will by default skip evaluating certain plans [1]. The configuration option optimizer_search_depth also exists to limit the search depth of query plans, but it is not enabled by default [2].
Modifying the cost constants¶
The cost used for each operation is configurable via the tables server_cost and engine_cost that reside in the mysql system database. Here are the default values as used in MySQL 8.0:
| Cost | Operation |
|---|---|
| 40 | disk_temptable_create_cost |
| 1 | disk_temptable_row_cost |
| 2 | memory_temptable_create_cost |
| 0.2 | memory_temptable_row_cost |
| 0.1 | key_compare_cost |
| 0.2 | row_evaluate_cost |
| 1 | io_block_read_cost |
| 1 | memory_block_read_cost |
Tip
MySQL 8.0 introduces a new feature where the cost model adapts to the percentage of the index that is in memory. The cost model in prior versions of MySQL always assumed that IO was required to access a page.
Cost itself is a logical unit that represents resource usage. A single unit no longer has an exact meaning, but it’s origin can be traced back to being one random IO on a 1990s hard drive.
As hardware improves, it may not do so at a consistent rate for all components (i.e., latency to storage has improved substantially with SSDs). Similarly, as software addresses changes in hardware (with features such as compression), resource consumption can also change. Having configurable cost constants allows for refinement to handle these cases.
Example 4 shows that changing the row_evaluate_cost to be five times higher has the effect that table scans become a lot more expensive (versus eliminating work via an index). This results in the optimizer choosing to use the p (Population) index that was created in Example 2.
Example 4: Increasing the cost of row evaluation makes table scans more expensive
# Increase the cost from 0.2 to 1.0
UPDATE mysql.server_cost SET cost_value=1 WHERE cost_name='row_evaluate_cost';
FLUSH OPTIMIZER_COSTS;
# in a new session
EXPLAIN FORMAT=JSON
SELECT * FROM Country WHERE continent='Asia' and population > 5000000;
{
"select_id": 1,
"cost_info": { # Since row evaluate is 5x higher
"query_cost": "325.01" # The total cost for the query
}, # has gone up!
"table": {
"table_name": "Country",
"access_type": "range", # But it will execute as a range
"possible_keys": [
"p"
],
"key": "p",
"used_key_parts": [
"Population"
],
"key_length": "4",
"rows_examined_per_scan": 108,
"rows_produced_per_join": 15,
"filtered": "14.29",
"index_condition": "(`world`.`Country`.`Population` > 5000000)",
"cost_info": {
"read_cost": "309.58",
"eval_cost": "15.43",
"prefix_cost": "325.01",
"data_read_per_join": "3K"
},
"used_columns": [
"Code",
"Name",
"Continent",
"Region",
"SurfaceArea",
"IndepYear",
"Population",
"LifeExpectancy",
"GNP",
"GNPOld",
"LocalName",
"GovernmentForm",
"HeadOfState",
"Capital",
"Code2"
],
"attached_condition": "(`world`.`Country`.`Continent` = 'Asia')"
}
}
}
Warning
Be careful when modifying cost constants, as a number of your query plans could change for the worse! This is shown here for demonstration purposes; in most production situations you will be better served by adding a query hint.
Warning
Be careful to reset costs before proceeding onto the other examples:
UPDATE mysql.server_cost SET cost_value=NULL WHERE cost_name='row_evaluate_cost';
FLUSH OPTIMIZER_COSTS;
# close session
Metadata and Statistics¶
As demonstrated in Example 3, the distribution of data can affect the cost of execution plans. The optimizer makes use of both the data dictionary and statistics to as part of its decision process.
Metadata¶
| Index Information | Uniqueness | Nullability | |
|---|---|---|---|
| Description | The dictionary provides a list of indexes per table. | If an index is unique, it can be used as part of a permanent transformation, shortcutting some parts of planning. | The optimizer needs to handle potential null values correctly. Nullability of a column can affect the use of some execution plans. |
Statistics¶
| Table Size | Cardinality | Range Estimates | |
|---|---|---|---|
| Description | Provides an estimate of the total table size. | Samples a small number of random pages (default 20), and extrapolates to determine the number of unique values in the indexed column. | The optimizer provides InnoDB with a minimum and a maximum value and receives back an estimate of the number of rows in the range. |
| Used For | All Columns | Indexed Columns | Indexed Columns |
| Calculated | In advance | In advance | On demand |
| Automatically Updated | During Regular Operation [3] | After 10% of the table has changed | N/A |
| Manually Updated | ANALYZE TABLE |
ANALYZE TABLE |
N/A |
| Configuration Options | N/A | Number of pages to sample [4] | Maximum # of index dives [5] Maximum memory usage [6] |
| Accuracy | Least Accurate | Can be subject to distribution skew | Most Accurate |
| Commonly Used For | Determining table scan cost. May be used for join order (largest table first) when lack of indexes. | Determining join order. Also used when range estimates exceed maximum # of index dives. | Used to evaluate predicates
(i.e., it looks at the
possible indexes that could
be used, and estimates how
many rows would match). A
range estimate was used to
determine that population
> 5000000 should not use
an index. |
Tip
Because of statistics, seemingly identical queries in QA and production may execute very differently. Even a query plan in production can change over time as data distribution does.
| [1] | The default optimizer_prune_level=1. To disable this heuristic and evaluate all plans, set it to zero. http://dev.mysql.com/doc/refman/5.7/en/controlling-query-plan-evaluation.html |
| [2] | The default optimizer_search_depth=64. Lower values may reduce plan evaluation time, as the cost of potentially less optimal plans. |
| [3] | Statistic are updated during regular operation, but not in a manner which is guaranteed to be accurate. |
| [4] | The number of pages sampled can be changed with innodb_stats_persistent_sample_pages. A higher value may produce more accurate estimates (at some increase to cost generation). |
| [5] | The optimizer will switch to cardinality estimates when IN lists exceed eq_range_index_dive_limit items (default: 200). |
| [6] | The range optimizer is limited to range_optimizer_max_mem_size (default: 8M). Queries that use multiple IN lists could exceed this, as the combination of options may be expanded internally. |